はじめてのGAN
今回はGAN(Generative Adversarial Network)を解説していきます。
GANは“Deep Learning”という本の著者でもあるIan Goodfellowが考案したモデルです。NIPS 2016でもGANのチュートリアルが行われるなど非常に注目を集めている分野で、次々に論文が出てきています。
また、QuoraのセッションでYann LeCunが、この10年の機械学習で最も面白いアイディアと述べていたりもします。
“The most interesting idea in the last 10 years in ML, in my opinion.”
–Yann LeCun
GANは聞いたことはあるけれどあまり追えてないという人向けに基礎から解説していきたいと思います。それでは順に見ていきましょう。
目次
基礎理論
この章ではGANの基本を解説していきます。
生成モデル
訓練データを学習し、それらのデータと似たような新しいデータを生成するモデルのことを生成モデルと呼びます。別の言い方をすると、訓練データの分布と生成データの分布が一致するように学習していくようなモデルです。GANはこの生成モデルの一種です。
通常、モデルが持つパラメータ数に対して訓練データの量が圧倒的に大きいため、モデルは重要な特徴を捉えることを求められます。
生成モデルには、GAN以外にもVAE(Variational Autoencoder)など他にも注目されているモデルがあり、それぞれ長所・短所があります。例えば、GANは学習が不安定ですが、他の手法に比べてくっきりとした画像が生成される傾向があります。今回はこのGANに焦点を当てて解説していきます。VAEなどはまた別の機会に紹介できればと思います。
GANの仕組み
GANではgeneratorとdiscriminatorという2つのネットワークが登場します。Generatorは訓練データと同じようなデータを生成しようとします。一方、discriminatorはデータが訓練データから来たものか、それとも生成モデルから来たものかを識別します。
この関係は紙幣の偽造者と警察の関係によく例えられます。偽造者は本物の紙幣とできるだけ似ている偽造紙幣を造ります。警察は本物の紙幣と偽造紙幣を見分けようとします。
次第に警察の能力が上がり、本物の紙幣と偽造紙幣をうまく見分けられるようになったとします。すると偽造者は偽造紙幣を使えなくなってしまうため、更に本物に近い偽造紙幣を造るようになります。警察は本物と偽造紙幣を見分けられるようにさらに改善し…という風に繰り返していくと、最終的には偽造者は本物と区別が付かない偽造紙幣を製造できるようになるでしょう。
GANではこれと同じ仕組みで、generatorとdiscriminatorの学習が進んでいきます。最終的には、generatorは訓練データと同じようなデータを生成できるようになることが期待されます。このような状態では、訓練データと生成データを見分けることができなくなるため、discriminatorの正答率は50%になります。
GANはGoodfellow et al. (2014)によって最初に提案されました。この研究ではgeneratorもdiscriminatorもどちらも基本的には多層パーセプトロンで、ドロップアウトを使って学習させています(一部CNNをつかっているものもあります)。
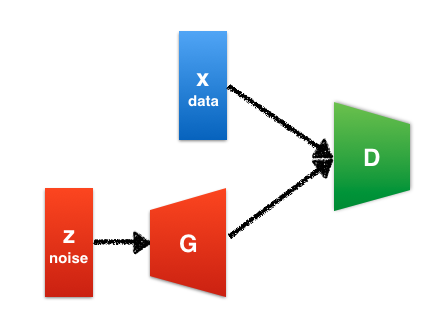
GANの概念図
大まかにGANの仕組みが分かったので、次に数式を使って見てみましょう。\(G\)はgenerator、\(D\)はdiscriminator、\(\boldsymbol{x}\)は訓練データ、\(\boldsymbol{z}\)はノイズを表します。
\(G\)はノイズ\(\boldsymbol{z}\)を入力としてデータを生成します。\(D(\boldsymbol{x})\)は、そのデータが訓練データである確率を表します。確率なのでスカラーです。\(D\)は訓練データと生成データに対して正しくラベル付けを行う確率を最大化しようとします。一方、\(G\)は\(\log (1 - D(G(\boldsymbol{z}))) \)を最小化しようとします。これらをまとめて以下のように表現します。
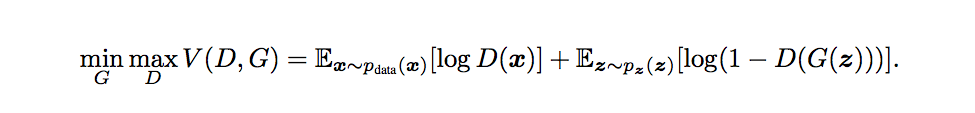
\(D\)がうまく分類できるようになると、\(D (\boldsymbol{x}) \)が大きくなり、\( \log D(\boldsymbol{x}) \)が大きくなります。また、偽物だとばれて\( D(G(\boldsymbol{z})) \)は小さくなるため、\(\log (1 - D(G(\boldsymbol{z}))) \)は大きくなります。一方、\(G\)が訓練データに似ているものを生成できるようになると、\(D\)がうまく分類できなくなるため\( D(G(\boldsymbol{z})) \)は大きくなり、\(\log (1 - D(G(\boldsymbol{z}))) \)は小さくなるという構造になっています。
学習時は、以下のようにdiscriminatorとgeneratorを交互に更新していきます。

実験結果
Goodfellow et al. (2014)の実験結果を見てみましょう。黄色い枠で囲まれている画像は訓練データで、それ以外は生成された画像です。訓練データによく似た画像を生成できている様子が分かります。

DCGAN
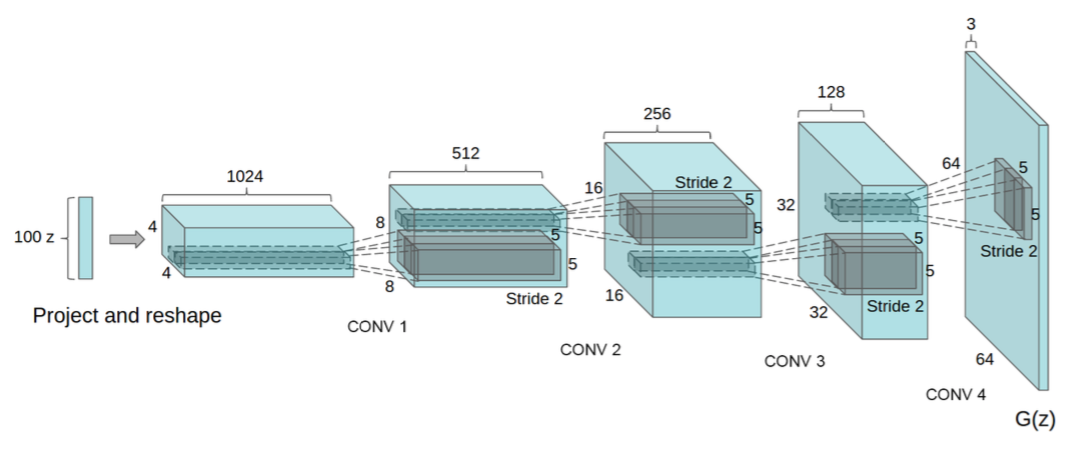
この章では、Radford et al. (2015)によって提案されたDCGAN(Deep Convolutional GAN)というモデルを紹介していきます。下図のように、名前の通りCNN(convolutional neural network)を使ったモデルになっています。CNNは画像関連を中心に大きな成功を収めているモデルであり、画像を生成するのであればやはりGANでもCNNを使うのがよいと考えられます。
CNNを使ったGANで最初に高解像度画像の生成に成功したのはLAPGANだと思いますが、何段にも分けて画像を生成する必要がありました(この記事の後半でも紹介します)。DCGANでは一発で高解像度画像を生成することに成功しています。
また、GANは学習が難しいことで知られていますが、この論文では学習をうまく進めるための様々なテクニックが紹介されています。2015年の論文ですが、未だに役に立つテクニックなので、ここでもそれらを紹介していきます。
プーリングをやめる
CNNでは最大プーリングを使ってダウンサンプリングするのが一般的ですが、discriminatorではこれをストライド2の畳み込みに置き換えます。
Generatorの方では、fractionally-strided convolutionを使ってアップサンプリングします。(余談:これはdeconvolutionと呼ばれることもありますが、deconvolutionというのは既に他の手法に割り当てられた名前であるため厳密には間違いです。そのため、fractionally-strided convolutionやtransposed convolutionという名前なども使われます。間違いと分かっていても言いやすいのでdeconvolutionと呼んでいる人も多い気がします。)
全結合層をなくす
CNNでは最後の方の層は全結合層になっていることがよくありますが、discriminatorからこれを取り除き、global average poolingに置き換えます。
Global average poolingはLin et al. (2013)で提案された手法です。AlexNetやVGGのような従来のCNNでは、畳み込み層で特徴を抽出し、最後は全結合層で分類するという構造になっていますが、global average poolingでは、全結合層の代わりに一つの特徴マップに一つのクラスを対応させるという方法で分類を行います。特徴マップごとの平均を取り、そのベクトルをソフトマックス分類器にかけます。下図を見ると分かりやすいかと思います。
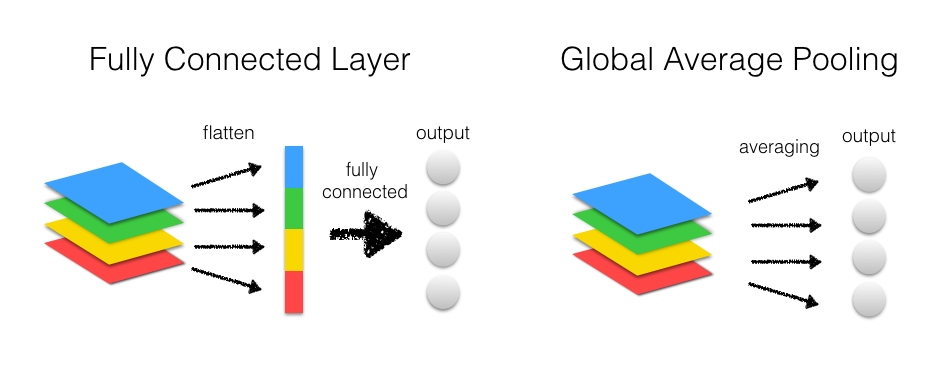
全結合層では通常ドロップアウトを使って過学習を防ぐ必要がありますが、global average poolingではパラメータがなくなるため、過学習を防ぐ効果があります。
Radford et al. (2015)によると、global average poolingを使うと安定性は増すものの、収束が遅くなってしまうようです。
Batch Normalizationを使う
最近のモデルではbatch normalizationがよく使われます。各層でのデータ分布を正規化してやることにより、学習を速くしたり、パラメータの初期化をそれほど気にしなくて済むようになります。また、過学習を防ぐ効果もあります。
DCGANではbatch normalizationをgeneratorとdiscriminatorの両方に適用します。但し、全ての層に適用すると不安定になってしまうようで、generatorの出力層と、discriminatorの入力層には適用しないようにします。
Leaky ReLUを使う
Generatorでは活性化関数に出力層だけTanhを使いますが、それ以外の層では全てReLUを使います。一方、discriminatorの方では全ての層でLeaky ReLUを使います。
Leaky ReLUについてはあまり馴染みがない人もいるかもしれないので、簡単に説明しておきたいと思います。
デフォルトの活性化関数として使われるReLUは\( f(x) = \max(0, x) \)と表されるのに対して、Leaky ReLUは\( f(x) = \max(\alpha x, x) \)と表されます。下図のような関数形になっています。DCGANでは\( \alpha = 0.2 \)という値が使われています。(この\( \alpha \)も含めて学習してしまおうというのがPReLUです。)
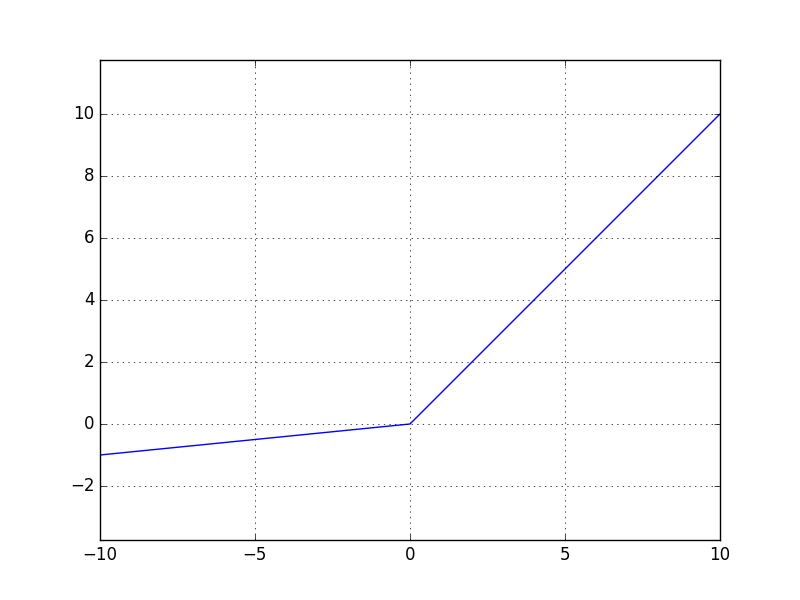
Leaky ReLU
\( x \leq 0 \)の領域を\( 0 \)から\( \alpha x \)にすることで何が改善されるのでしょうか?ReLUでは\( x \leq 0 \)の領域では勾配が0になってしまうため、誤差逆伝播がそこでストップし、それ以上そのニューロンの学習は進まなくなってしまいます。Leaky ReLUは勾配がゼロにならず、この問題を回避することができます。
余談ですが、\( \alpha \)も含めて学習してしまうPReLUの方がLeaky ReLUの方が良いのではないかと思うかもしれませんが、そう単純でもありません。PReLUは過学習を起こしてしまうリスクがあるようです(参考:Xu et al. (2015))。
実験結果
ベッドルームの画像のデータセットを使って学習した結果です。一見本物と見間違ってしまいそうなレベルの画像を生成できていることが分かります。

もう一つ面白い結果を紹介します。Word2Vecという単語ベクトルで「王様」-「男」+「女」=「女王」という演算ができることは有名ですが、GANにおける入力である\(z\)ベクトルを使っても同様の演算を行うことができます。下の例では、「サングラスをかけた男」-「男」+「女」=「サングラスをかけた女」という演算を行っています。

その他のテクニック
ここまでDCGANについて解説してきましたが、GANの学習をうまく進めるためのテクニックは他にもたくさんあります。
例えば、How to Train a GAN?というページに様々なテクニックがまとまっています。また、OpenAIの最初の論文であるImproved Techniques for Training GANsも参考になります。
実装
それでは実装してみましょう。GANを使った面白い例はたくさんあるのですが、ここではGANの理解を深めることが目的なので、シンプルなデータセットであるMNISTを使用します。
KerasでもDCGANの実装はいくつか公開されています。ここではこちらのコードをベースにして実装していきます。どれもDCGANと言いつつも、活性化関数がLeaky ReLUになっていなかったり、batch normalizationが入っていなかったりと、DCGANの論文とは異なる設定が多いため、なるべく論文に近い形に変更しながら実装していきます。
まずはgeneratorを作成します。
from keras.models import Sequential
from keras.layers import Dense, Activation, Reshape
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import UpSampling2D, Convolution2D
def generator_model():
model = Sequential()
model.add(Dense(input_dim=100, output_dim=1024))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(128*7*7))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Reshape((128, 7, 7), input_shape=(128*7*7,)))
model.add(UpSampling2D((2, 2)))
model.add(Convolution2D(64, 5, 5, border_mode='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(UpSampling2D((2, 2)))
model.add(Convolution2D(1, 5, 5, border_mode='same'))
model.add(Activation('tanh'))
return model
入力として100次元のベクトルがあり、これが全結合層を経て、畳み込み層に7x7の画像として与えられます。そこから2回upsamplingが行われることによって、MNISTと同じサイズの28x28の画像が出力されます。
DCGAN論文の通りに、活性化関数は基本的にReLUで、出力層だけTanhです。出力層以外の層にはbatch normalizationも入れています。
次にdiscriminatorを作成します。
from keras.layers.advanced_activations import LeakyReLU
from keras.layers import Flatten, Dropout
def discriminator_model():
model = Sequential()
model.add(Convolution2D(64, 5, 5,
subsample=(2, 2),
border_mode='same',
input_shape=(1, 28, 28)))
model.add(LeakyReLU(0.2))
model.add(Convolution2D(128, 5, 5, subsample=(2, 2)))
model.add(LeakyReLU(0.2))
model.add(Flatten())
model.add(Dense(256))
model.add(LeakyReLU(0.2))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
出力層を除いて活性化関数はLeaky ReLUにしています。また、プーリングの代わりに、subsample=(2, 2)としてストライド2の畳み込みを行うことによってダウンサンプリングしています。
DCGAN論文には”Remove fully connected hidden layers for deeper architectures.”とあります。深いニューラルネットワークの場合は、全結合層を取り除き、global average poolingを使った方が良いようですが、このdiscriminatorは浅いのでそのまま全結合層にしておきます。
また、実はbatch normalizationが入っていません。生成画像と本物の画像を同じバッチに入れているのがよくなさそうなので分けてみるなど、色々と試してみたのですがこちらの記事にもあるようにどうもうまくいきませんでした。(一応動くことには動くのですが、クオリティが落ちてしまいました。)
こちらの記事によると、discriminatorにbatch normalizationを入れるとdiscriminatorが強くなりすぎてうまくいかない場合があるとのことなので、そういうことなのかもしれません。他のKerasでの実装例を見ても、discriminatorにはbatch normalizationが入っていないものがほとんどです。ここではこれ以上は深堀らないでおくことにします。
生成画像を並べて表示するための関数も用意しておきます。
import math
import numpy as np
def combine_images(generated_images):
total = generated_images.shape[0]
cols = int(math.sqrt(total))
rows = math.ceil(float(total)/cols)
width, height = generated_images.shape[2:]
combined_image = np.zeros((height*rows, width*cols),
dtype=generated_images.dtype)
for index, image in enumerate(generated_images):
i = int(index/cols)
j = index % cols
combined_image[width*i:width*(i+1), height*j:height*(j+1)] = image[0, :, :]
return combined_image
最後に学習部分です。
import os
from keras.datasets import mnist
from keras.optimizers import Adam
from PIL import Image
BATCH_SIZE = 32
NUM_EPOCH = 20
GENERATED_IMAGE_PATH = 'generated_images/' # 生成画像の保存先
def train():
(X_train, y_train), (_, _) = mnist.load_data()
X_train = (X_train.astype(np.float32) - 127.5)/127.5
X_train = X_train.reshape(X_train.shape[0], 1, X_train.shape[1], X_train.shape[2])
discriminator = discriminator_model()
d_opt = Adam(lr=1e-5, beta_1=0.1)
discriminator.compile(loss='binary_crossentropy', optimizer=d_opt)
# generator+discriminator (discriminator部分の重みは固定)
discriminator.trainable = False
generator = generator_model()
dcgan = Sequential([generator, discriminator])
g_opt = Adam(lr=2e-4, beta_1=0.5)
dcgan.compile(loss='binary_crossentropy', optimizer=g_opt)
num_batches = int(X_train.shape[0] / BATCH_SIZE)
print('Number of batches:', num_batches)
for epoch in range(NUM_EPOCH):
for index in range(num_batches):
noise = np.array([np.random.uniform(-1, 1, 100) for _ in range(BATCH_SIZE)])
image_batch = X_train[index*BATCH_SIZE:(index+1)*BATCH_SIZE]
generated_images = generator.predict(noise, verbose=0)
# 生成画像を出力
if index % 500 == 0:
image = combine_images(generated_images)
image = image*127.5 + 127.5
if not os.path.exists(GENERATED_IMAGE_PATH):
os.mkdir(GENERATED_IMAGE_PATH)
Image.fromarray(image.astype(np.uint8))\
.save(GENERATED_IMAGE_PATH+"%04d_%04d.png" % (epoch, index))
# discriminatorを更新
X = np.concatenate((image_batch, generated_images))
y = [1]*BATCH_SIZE + [0]*BATCH_SIZE
d_loss = discriminator.train_on_batch(X, y)
# generatorを更新
noise = np.array([np.random.uniform(-1, 1, 100) for _ in range(BATCH_SIZE)])
g_loss = dcgan.train_on_batch(noise, [1]*BATCH_SIZE)
print("epoch: %d, batch: %d, g_loss: %f, d_loss: %f" % (epoch, index, g_loss, d_loss))
generator.save_weights('generator.h5')
discriminator.save_weights('discriminator.h5')
DCGAN論文では、Adamオプティマイザの学習係数は0.0002、\(\beta_1\)は0.5となっていますが、これだとうまく進みませんでした。discriminatorの学習だけ早く進んでしまうようです。結局こちらの記事を参考に、上記の値を採用しました。
Discriminatorの重みを更新し、次にdiscriminatorの重みを固定した状態でgeneratorの重みを更新するという流れを繰り返しています。discriminator.trainable = Falseとしているため、discriminatorの重みが更新されなくなってしまうのではないかと思うかもしれませんが、大丈夫です。trainableプロパティの変更を反映するためにはcompile()を呼ぶ必要があり、重みが固定されるのはdcganの中のdiscriminatorの部分だけになります。詳しくは公式ドキュメントなどを参考にしてみてください。
dcgan.train_on_batch(noise, [1]*BATCH_SIZE)の所が少し分かりにくいかもしれません。生成画像をラベルが1の本物の画像として扱うことにより、discriminatorを騙そうとしています。\(- \log (1 - D(G(\boldsymbol{z}))) \)を最大化する代わりに、\(- \log (D(G(\boldsymbol{z}))) \)を最小化するように学習していることになります。
学習初期においてgeneratorから生成された画像はかなり質が低いため、簡単にdiscriminatorに見破られてしまいます。少しパラメーターを変えてもどれも見破られてしまうため、どのような変更を加えたらdiscriminatorをだませるような画像を生成できるのか分かりにくい状態にあります。言い換えると、学習初期には勾配が小さくなりがちです。Goodfellow et al. (2014)にあるように、\(- \log (1 - D(G(\boldsymbol{z}))) \)の代わりに\(- \log (D(G(\boldsymbol{z}))) \)を使うことによって、より大きな勾配を得られるようにしています。

Epoch 20までの学習過程
結果はこのようになり、手書きっぽい数字を出力することができました。もう少し長く計算すると、もう少しクオリティが上がるはずです。
また、ハイパーパラメータを色々と変えて実験していたのですが、長時間計算していると出力が全部1になってしまうことがよくありました。敢えて色んな数字を出力せずとも、単純に全部1にしてdiscriminatorを騙せてしまうということなのかもしれません。このようなモードの崩壊はよく知られている問題で、対処法も提案されてきています。
論文紹介
この章ではGANに関連する論文を幾つか紹介していきます。たくさんあるので全部紹介することはできませんが、論文を読み進めていく上での参考になればと思います。この記事をアップデートする形で、他の論文も紹介していく予定です。
GAN関連の論文はAdversarialNetsPapersというリポジトリにまとまっています。また、Ian GoodfellowによるGANのチュートリアルも公開されていて、こちらもおすすめです。
このLAPGAN(Laplacian Pyramid of Generative Adversarial Networks)はCNNを使ったモデルで、下図のように段階的により高解像度な画像を生成していくのが特徴です。
GANは学習が不安定という問題がありました。いきなり高解像度の画像を生成するのは難しいかもしれません。しかし、低解像度の画像を生成することは簡単でしょう。その低解像度画像を使って、もう少しだけ解像度の高い画像を生成することもそれほど難しくはないだろう、というのがLAPGANの主なアイディアです。これを繰り返していくことによって、最終的に解像度の高い画像を生成します。
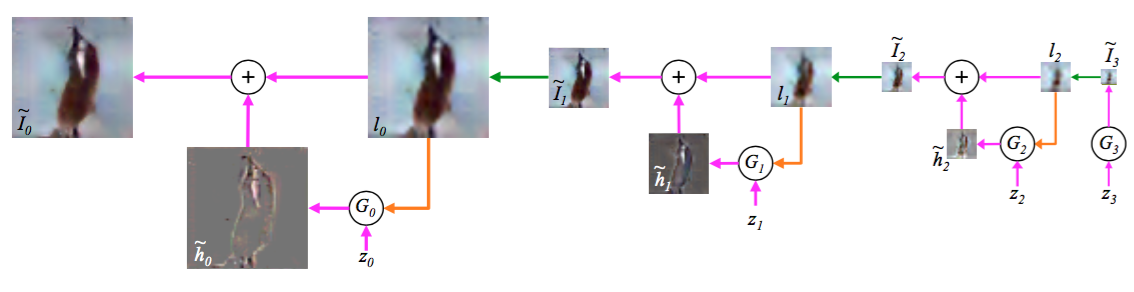
図の流れに従ってもう少し詳細を見ていきましょう。まず、ノイズ\(z_3\)を取り出し、generator \(G_3\)が\(\tilde{I}_3\)を生成します。これをupsampleし、\(l_2\)を生成します。これとノイズ\(z_2\)を\(G_2\)に与えることにより、画像の差分である\(\tilde{h}_2\)を生成します。\(l_2\)と\(\tilde{h}_2\)を足し合わせることより\(\tilde{I}_2\)が出来上がります。
この流れを繰り返していくことにより、最終的な出力画像を得ます。図では3段階になっていますが、これはあくまでも一例で、最終的に得たい画像の解像度などによって段数が違ってきます。

結果を見ると本物っぽい画像が生成されている様子が分かります。CC-LAPGANというのはclass conditional LAPGANのことで、「飛行機」や「犬」などクラスを指定して生成できるようにしたバージョンのLAPGANです。
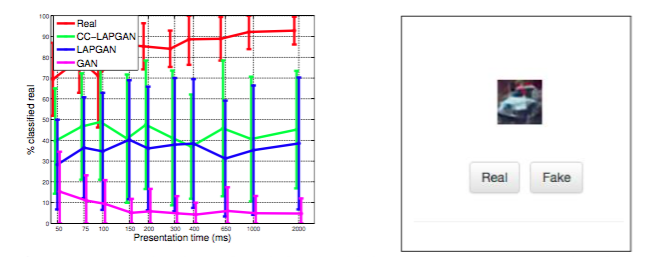
また、右図のようなUIで本物に見えるか偽物に見えるか人間に評価してもらうというテストも行っています。グラフを見ると、オリジナルのGANでは10%以下の割合でしか本物に見えないようですが、LAPGANでは約40%となっています。ちなみに本物の画像では90%程度の値となっています。
これはGANを超解像(super-resolution)に応用した研究です。元々はMagic Pony Technologyという会社が行っていた研究で、$150MでTwitterに買収されています。その後にこの論文が出ています。
超解像というのは、低解像度画像から高解像度画像を生成する技術のことです。低解像度画像を入力とし、高解像度画像を出力するようにニューラルネットワークを訓練します。教師あり学習は、データセットを用意することが困難であることがよくあります。既存の手法で高解像度画像から低解像度画像を生成する事は容易であるため、超解像では簡単にデータセットを用意することができるという特徴があります。
単純には、autoencoder型のCNNを用意し、損失関数をピクセルレベルでのMSE(平均二乗誤差)にして学習させれば良いと考えられます。この方法である程度はうまく行くのですが、どうしてもぼやけた画像になりがちです。理由は以下です。
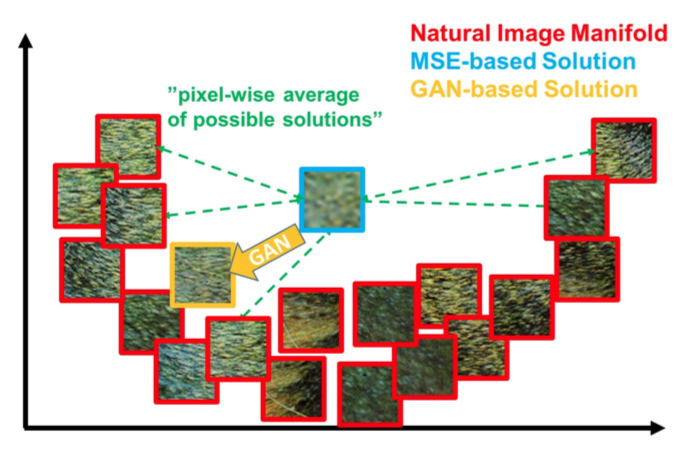
低解像度画像から高解像度を生成する時に答えは一つではありません。図中の赤枠の画像のように、自然に見えるパターンというのは何パターンも考えられるわけです。MSEベースで考えると、どのパターンと比較して損失を計算することになったとしても、それなりに損失が小さくなるように平均的なぼやけた画像が生成されてしまいます。
この問題を解決するためにGANを使うことを考えます。GANではdiscriminatorを騙すことさえできればどんなパターンでも良いため、平均的な画像ではなく、本物っぽいシャープな画像が生成されることが期待されます。
上記の議論を踏まえ、下記のような損失関数を採用します。
\( l_\text{Gen}^\text{SR} \) はGANに関する損失です。\( l^\text{SR}_\text{VGG} \) はいわゆるVGG lossです。ピクセルレベルでの比較ではなく、VGGのある層における特徴マップで比較します。こちらの方が、ピクセルレベルで比較するよりもシャープな画像が得られることが分かっています。VGGを損失関数として使う手法は他の研究でも使われていて、前回のブログでも少し触れています。
モデルは下図のようにResNetとなっています。
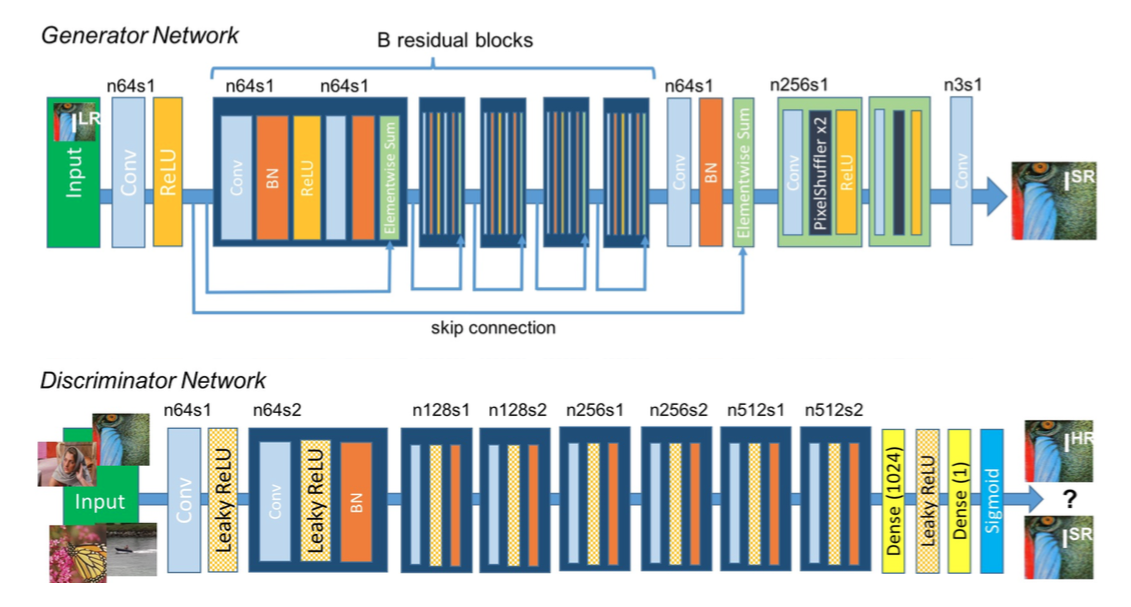
結果がこちらです。低解像度画像を縦横4倍ずつの高解像度にしています。SRResNetというのは、GANを使わずにMSEのみで学習させた比較用のモデルです。SRGANでは非常にはっきりとした画像を生成できている様子が分かります。特に、頭や首周りの細かい構造を見ると、SRResNetではぼやけてしまっているのに対し、SRGANでははっきりしていることが分かります。はっきりとはしていますが、オリジナルの画像と比較すると必ずしもそれが本物ではないことも分かります。Discriminatorをだますためには、「本物っぽく」ありさえすれば良いからです。

これまでは似たような問題設定でも個別のモデルで個別の研究として扱われてきました。この研究では下図のように似たようなタスクは一つのモデルでやってしまおうという研究です。
衛星写真をマップにしたり、白黒画像をカラー化したり、昼の写真を夜にしたりと、モデルで様々なタスクをこなすことができています。
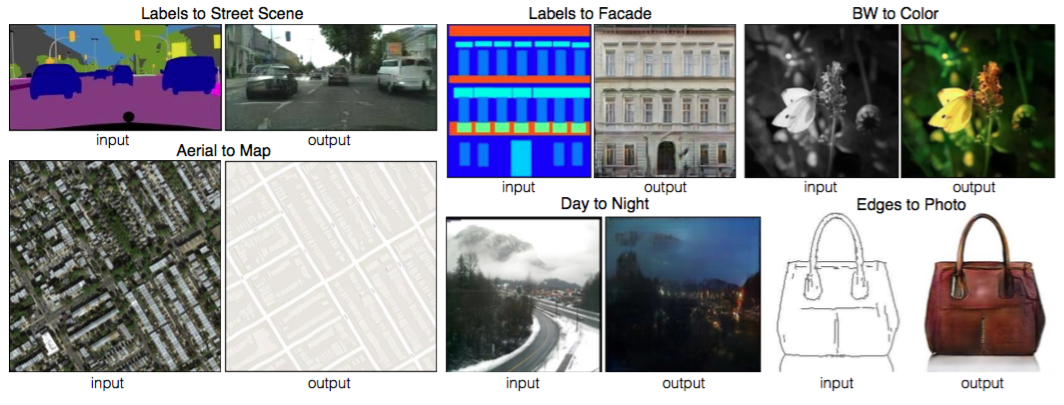
モデルはConditional GANになっていて、入力画像はGとDの両方に与えられます。また、通常Gはノイズをサンプルしますが、このモデルでは直接ノイズをサンプルするのではなく、複数の層に渡ってドロップアウトという形でノイズを入れるようにしています。ドロップアウトは普通は学習時だけに入れるものですが、このモデルではテスト時にも入れるようになっています。
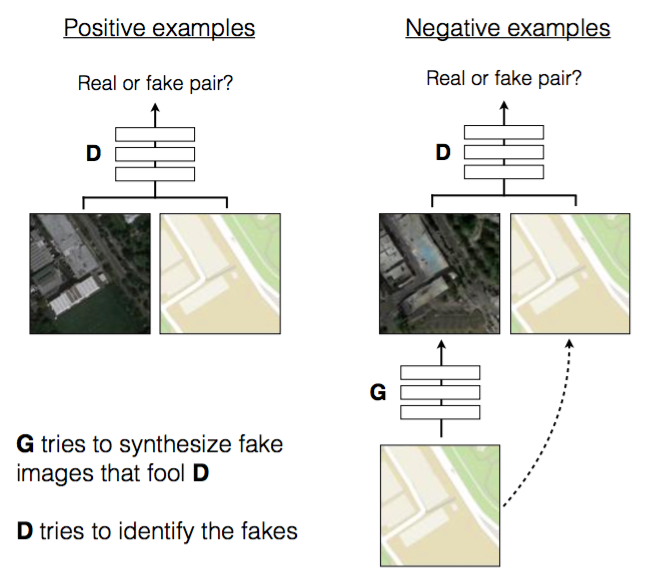
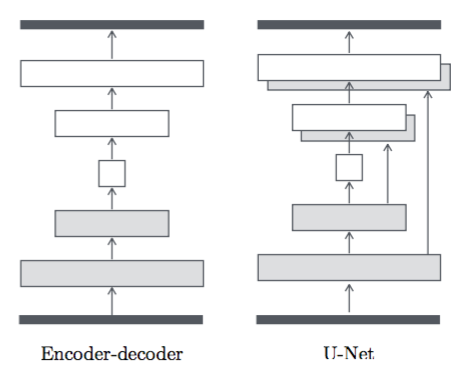
GeneratorにはU-Netというencoder-decoder間にskip connnectionがあるモデルが採用されています。こうすることで、エッジのような浅い層で獲得された特徴も直接利用できるようになり、よりクオリティの高い画像が得られるようになります。
一つのモデルでこれだけ面白い様々な変換ができてしまうのはすごいですね。ソースコードも公開されているので自分で実験してみるのも楽しいかもしれません。
これはGANを二段階にすることにより、クオリティの高い画像を生成することに成功した研究です。結果の図を見ると分かりやすいです。
テキストに合わせた画像を生成するというタスクになっています。画像はStage-IとStage-IIの二段階に分けて生成します。Stage-Iでは、色やレイアウトなど大まかな部分を描き、低解像度画像を出力します。Stage-IIでは、その低解像度画像とテキストを元に詳細部分を描き、クオリティの高い高解像度画像を生成します。

モデルの詳細はこのようになっています。Stage-IもStage-IIもconditional GANになっています。
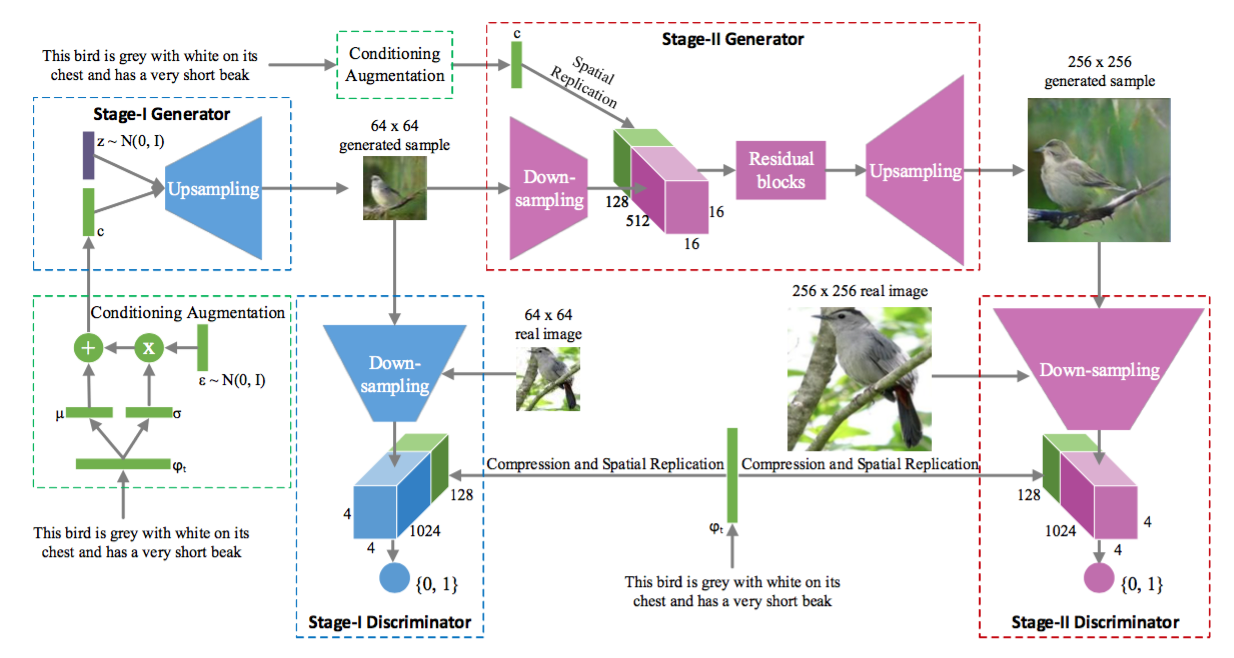
Stage-Iのgeneratorにはノイズとテキスト(text embedding)が入力として与えられます。Text embeddingをそのまま与えれば良さそうな気もしますが、それだと次元やデータ量の関係でうまくいかないようで、text embeddingからガウス分布を作り、そこからサンプルするという手法を用いています。
Stage-IIのgeneratorには、Stage-Iで生成された画像とテキストが入力として与えられます。Discriminatorの方はStage-IもStage-IIもほとんど構造で同じで、画像とテキストが与えられます。
結果をもう少し見てみましょう。

Stage-Iで大まかに描いて、Stage-IIで詳細を描けていることが分かります。もう少し細かく見てみると、Stage-Iでの失敗をStage-IIで修正できる場合もあることも分かります。例えば、右から3列目を見ると本当は赤茶色にしなければならなかった部分がStage-Iでは青くなってしまっていますが、Stage-IIうまく修正してくれている様子が分かります。
もう一つ結果を紹介します。

「真っ赤な鳥」から「真っ黄色な鳥」に向かって徐々に変化させていくというような実験です。スムーズに画像が変化していっている様子が分かります。StackGANは余りにもキレイな画像を生成できているので、単純に訓練データの画像をコピーして近い画像を表示しているのではないかと疑う人もいるかもしれませんが、上図はちゃんと生成していることを示す例の一つです。
それにしてもこんなにキレイな画像を生成できてしまうのは凄いですね。
SimGAN, Shrivastava et al. (2016)
秘密主義を貫いてきたAppleですが、最近Appleの研究者も論文を投稿できるようになりました。これがその最初の論文です。
教師あり学習では、ラベル付きのデータを手に入れるのにコストがかかるという問題があります。そこで人工的に作った画像(synthetic image)を使うという方法があります。ラベルも既に分かっているため、こちらのやり方の方が圧倒的に効率がよい場合があります。有名な例としてはMicrosoftのKinectがあります(参考)。
しかし、このやり方にも問題があります。Synthetic imageと本物の画像の違いが大きいと、synthetic imageを使って学習しても、実際に本物画像に対して使った時にうまく動かない場合があります。そこで、GANを使ってsynthetic imageをより本物っぽくしてしまおうというのがこの研究です。下図が分かりやすいです。
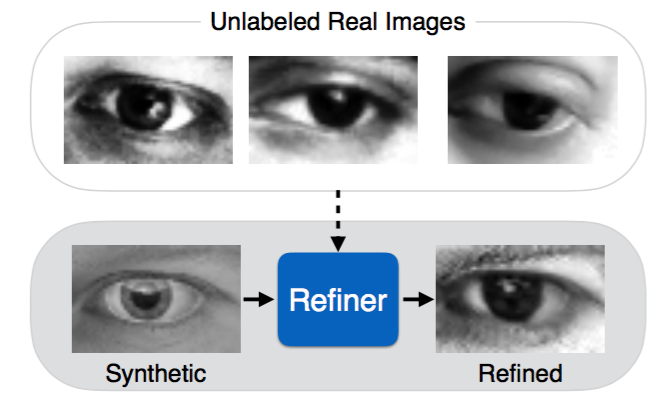
通常GANではノイズが入力になりますが、ここではsynthetic imageが入力となります。また、損失関数では、self-regularization lossという損失も考慮します。これは元のsynthetic imageとgeneratorによって生成された画像の差分を小さくするためのものです。なぜこれが必要かというと、例えば目の画像の場合、本物っぽく見えさえすれば何でもいいわけではなく、視線方向などを保ちたいからです。
また、よりクオリティの高い画像を生成するために幾つかの工夫が施されています。例えば、discriminatorに画像を与える時に、新しくできた生成画像だけでなく、過去の生成画像の一部も混ぜてやります。強化学習のExperience Replayっぽい感じで面白いです。
まとめ
そもそもGANとはどういうモデルかという所から始まり、学習をうまく進めるためのテクニックの紹介や実装を行いました。幾つか論文も紹介しましたが、面白い論文がまだまだたくさんあるので今後も紹介していければと思います。
参考文献
- Keras Documentation
- CS231n Convolutional Neural Networks for Visual Recognition
- Goodfellow et al. (2016) Book, Deep Learning, Ian Goodfellow Yoshua Bengio and Aaron Courville, Book in preparation for MIT Press
- OpenAI Blog, Generative Models
- Goodfellow et al. (2014), Generative Adversarial Nets
- Radford et al. (2015), UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
- Ian Goodfellow (2016), NIPS 2016 Tutorial: Generative Adversarial Networks
- ゼロから作るDeep Learning
- Xu et al. (2015), Empirical Evaluation of Rectified Activations in Convolution Network
- Denton et al. (2015), Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
- Deep generative image models using a laplacian pyramid of adversarial networks: Supplementary material
- Deep Learning Research Review Week 1: Generative Adversarial Nets
- Emily Denton: Generative image modeling with GAN
- Lin et al. (2013), Network In Network
- KerasでDCGAN書く
- Generating Faces with Torch
- Ledig et al. (2016), Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
- Shrivastava et al. (2016), Learning from Simulated and Unsupervised Images through Adversarial Training
- Isola et al. (2016), Image-to-Image Translation with Conditional Adversarial Networks
- Zhang et al. (2016), StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks