Kerasで学ぶ転移学習
前回記事では、KaggleのFacial Keypoints Detectionを題材にして、単純なニューラルネットワークから転移学習まで解説しました。
事前に学習した重みを読み込んだ後、全ての層で学習するのではなく、一部の層をフリーズさせることもできるという話を最後に少しだけしました。ちょうどその後、転移学習について詳細に解説しているKerasの公式ブログ記事が公開されましたこともあり、今回はこの記事を参考にしつつ、転移学習をメインに解説していきます。間違いがあれば指摘してください。今回もFacial Keypoints Detectionのデータを使って解説していくので、前回記事も是非合わせて読んでみてください。
また、Keras 1.0.4が公開されたのでまだの人はアップデートしておくと良いかと思います。
目次
転移学習
畳み込みニューラルネットワーク(convolutional neural network, CNN)をまっさらな状態から学習させることは、実際にはあまりありません。学習に使えるデータの量が限られていたり、学習に時間がかかったりするためです。
120万枚・1000クラスからなるImageNetを使って学習させると数週間ほどかかったりしますが、学習済みの重みが公開されています。そこでこの重みをうまく使うことによって、効率よく学習を行うことを考えます。主に以下の方法が考えられます。
一つは、CNNを特徴抽出器として利用する方法です。最後の全結合層を取り除き、その他の部分を特徴抽出器として扱います。例えば、AlexNetでこれを行うと、それぞれの画像に対して4096次元のベクトルが得られます。この特徴量を保存しておき、今度はこれを入力としてソフトマックスなどの分類器を学習させます。新しく付けた層だけを学習させ、それ以外の層をフリーズさせておくこともできますが、これだと毎回特徴を抽出し直すことになってしまうため、余計に計算時間がかかってしまいます。
他には、畳み込み層を学習し直す方法もあります。学習済みの重みの値を初期値として、ニューラルネットワーク全体で学習し直すことができます。ランダムに初期化した場合よりもより早く学習が収束することが期待できます。
また、一部の層をフリーズさせておき、それ以外の層だけを学習し直す方法もあります。
これらの方法を合わせて使うことも可能です。最後の全結合層を付け替えた場合、この層は他の層に比べて急速に学習が進むはずです。そのため、最初はその全結合層のみで学習を行い、ある程度学習が進んだ段階で全ての層で学習を行うという方法が考えられます。
新しく付け替えた全結合層以外をフリーズさせてしまうのではなく、学習係数を層によって変えるという方法も考えられます。この場合は、取り替えた全結合層で学習が速く進むように、他の層に比べて学習係数を大きくします。取り替えた全結合層以外の層では学習が進んでいるため、小さな学習係数を設定します。
ではどのように使い分ければ良いのでしょうか。①新しいデータの量、②新しいデータは事前学習に使用したデータと似ているか、の2つが特に重要です。
データが少ない・似ている データが少ないため、全体を学習し直すと過学習が起きてしまうかもしれません。また、事前学習に使用したデータと似ているため、上層の特徴をそのまま使用することができると考えられます。事前に学習したCNNを特徴抽出器として使用し、新しく付けた分類器でのみ学習するのが良いでしょう。
データが多い・似ている データが多いので過学習をあまり心配する必要がありません。多くの層は共通して使えると考えられるので、上層だけで学習しても良いですし、ネットワーク全体で学習することもできます。
データが少ない・似ていない これは転移学習が困難なパターンです。データが少ないので過学習を防ぐために上層だけを学習させたいところですが、似ていないデータを使って学習しているため、上層の特徴を使ってもうまく学習できないと考えられます。上層では目のようなものだったり特化した特徴を抽出しますが、下層ではエッジなどより一般的な特徴を抽出していると考えられます。上層ではなくどこか途中の層に分類器を繋ぐとうまくいくかもしれません。
データが多い・似ていない データが多いのでランダムに初期化された状態から学習することもできますが、事前学習した重みの値を初期値として学習することにより、効率良く学習できることが期待されます。下層は共通して使える部分が多いと考えられるからです。
Razavian et al. 2014では、ImageNetで学習したAlexNetを特徴抽出器として使った様々な実験結果をまとめています。抽出した特徴を入力として、線形SVMに学習させます。特徴抽出器はImageNetに最適化されているにも関わらず、ImageNetとは異なるデータセットから特徴を抽出し、線形SVMに学習させてもかなりうまくいくことが分かっています。CNNから抽出した特徴は割と一般的に使えるようです。
可視化
転移学習の実装に入る前に、まずは転移学習で使用することになる学習済みの畳み込みニューラルネットワーク(CNN)を可視化して調べてみましょう。この章ではKerasで可視化する方法を紹介したいと思います。可視化に興味がない場合は、この章は読み飛ばしてもらっても問題ありません。
フィルタによる活性化が最大(畳み込んだ値が最大)となる入力画像を作成してみます(フィルタの重み自体を可視化するわけではありません)。前回記事でKaggle Facial Keypoints Detectionのデータセットを使い、5000エポックまで学習させたモデルがあるのでそれを使います。可視化に必要となる重みのデータはこちらからダウンロードできます。model6_weights_5000.h5というファイルです。
Kerasの公式ブログを参考に実装を進めていきます。コードはGitHub上に置いておきました。ちなみに公式ブログの方ではVGG16というモデルを使って可視化を行っています。
from keras.models import Sequential
from keras.layers import Convolution2D, Activation, MaxPooling2D, Dropout
# 入力画像のサイズ
img_width = 96
img_height = 96
model.add(Convolution2D(32, 3, 3, input_shape=(1, 96, 96), name='conv1'))
first_layer = model.layers[-1]
input_img = first_layer.input
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.1))
model.add(Convolution2D(64, 2, 2, name='conv2'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Convolution2D(128, 2, 2, name='conv3'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.3))
layer_dict = dict([(layer.name, layer) for layer in model.layers])
このモデルのアーキテクチャは前回記事で紹介したものと基本的に同じです。畳み込み層の部分を可視化することを考えているので、全結合層は除いてあります。モデルのアーキテクチャも載せておきます。
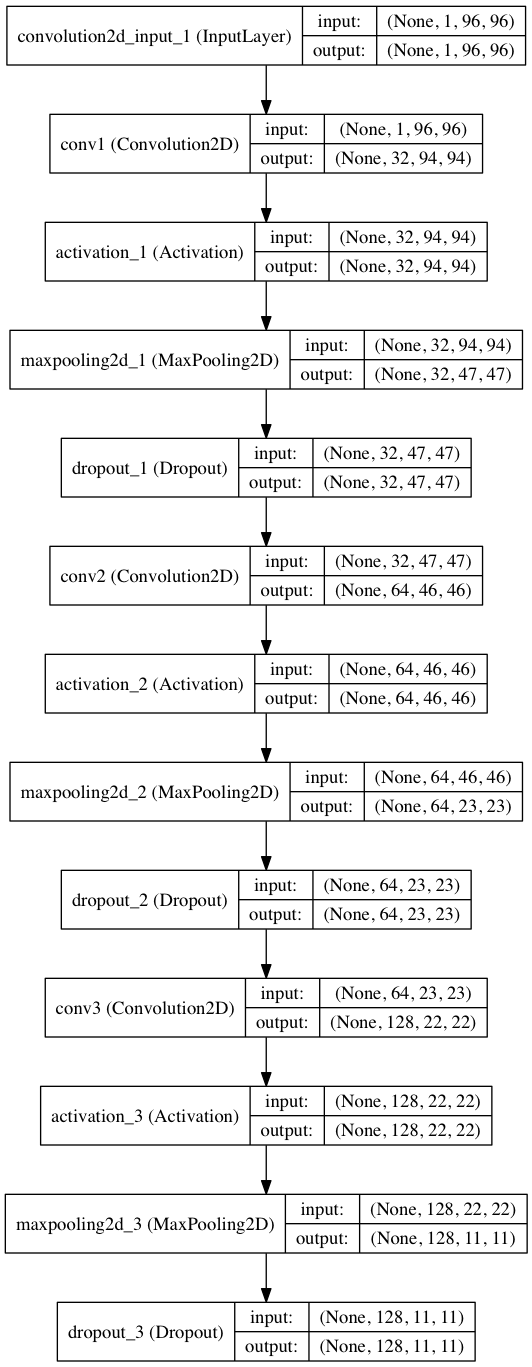
モデルのアーキテクチャは以下のようにして出力することができます。
from keras.utils.visualize_util import plot
plot(model, to_file="model.png", show_shapes=True)
次に、事前に学習しておいた重みを読み込みます。通常はmodel.load_weights()を使うだけで簡単に読み込めるのですが、ここでは使用することはできません。学習時には全結合層も存在していたのですが、このモデルでは全結合層が存在しないためエラーが起きてしまいます。そこで、層ごとに読み込んで行き、全結合層の手前まできたら終了させます。
import os
import h5py
from keras import backend as K
# https://github.com/elix-tech/kaggle-facial-keypoints からダウンロード
weights_path = '../examples/model6_weights_5000.h5'
assert os.path.exists(weights_path), 'Model weights not found (see "weights_path" variable in script).'
f = h5py.File(weights_path)
layer_names = [n.decode('utf8') for n in f.attrs['layer_names']]
weight_value_tuples = []
for k, name in enumerate(layer_names):
if k >= len(model.layers):
# 全結合層の重みは読み込まない
break
g = f[name]
weight_names = [n.decode('utf8') for n in g.attrs['weight_names']]
if len(weight_names):
weight_values = [g[weight_name] for weight_name in weight_names]
layer = model.layers[k]
symbolic_weights = layer.trainable_weights + layer.non_trainable_weights
if len(weight_values) != len(symbolic_weights):
raise Exception('Layer #' + str(k) +
' (named "' + layer.name +
'" in the current model) was found to '
'correspond to layer ' + name +
' in the save file. '
'However the new layer ' + layer.name +
' expects ' + str(len(symbolic_weights)) +
' weights, but the saved weights have ' +
str(len(weight_values)) +
' elements.')
weight_value_tuples += zip(symbolic_weights, weight_values)
K.batch_set_value(weight_value_tuples)
f.close()
print('Model loaded.')
少し長く見えるかもしれませんが、重みの数に矛盾がないか確認したりしながら層ごとに重みを読み込んで行っているだけです。ちなみにlayer_namesやmodel.layersの中身は以下のようになっています。
print('len layer names:', len(layer_names))
print('len model layers:', len(model.layers))
print('layer names:', layer_names)
print('model layer names:', [layer.name for layer in model.layers])
# 出力結果
# len layer names: 19
# len model layers: 12
# layer_names: [u'convolution2d_10', u'activation_17', u'maxpooling2d_10', u'dropout_5', u'convolution2d_11', u'activation_18', u'maxpooling2d_11', u'dropout_6', u'convolution2d_12', u'activation_19', u'maxpooling2d_12', u'dropout_7', u'flatten_4', u'dense_12', u'activation_20', u'dropout_8', u'dense_13', u'activation_21', u'dense_14']
# model layer names: ['conv1', 'activation_1', 'maxpooling2d_1', 'dropout_1', 'conv2', 'activation_2', 'maxpooling2d_2', 'dropout_2', 'conv3', 'activation_3', 'maxpooling2d_3', 'dropout_3']
この重みを層ごとに読み込んでいく部分は、実はKerasの公式ブログとは異なる書き方をしています。重みはHDF5ファイルとして保存されているのですが、そのフォーマットが最近変更されたようです。model6_weights_5000.h5というファイルはこの新しいフォーマットで保存されているため、上記のようにして重みを取り出す必要があります。ここははまりやすいポイントではないかと思います。
古いフォーマットで保存されているファイルを読み込む場合は、公式ブログと同様の方法で読み込むことができます。公式ブログで使われているvgg16_weights.h5というVGG16で事前学習した重みは、古いフォーマットで保存されています。
import h5py
weights_path = 'vgg16_weights.h5'
f = h5py.File(weights_path)
for k in range(f.attrs['nb_layers']):
if k >= len(model.layers):
break
g = f['layer_{}'.format(k)]
weights = [g['param_{}'.format(p)] for p in range(g.attrs['nb_params'])]
model.layers[k].set_weights(weights)
f.close()
print('Model loaded.')
次に、フィルタによる活性化が最大となる入力画像について考えます。どのようにしてそのような入力画像を作ることができるでしょうか。これは一つの最適化問題であると考えることができます。フィルタによる活性化が最大になるようにしたいので、単純にはいつものように勾配降下法(gradient descent)を使えば良いことになります(正確には最小化ではなく最大化なのでgradient ascent)。
まず、ある層(layer_name)のあるフィルタ(filter_index)による活性化を表す損失関数(loss)を定義します。(公式ブログに合わせてlossにしていますが、最大値を考えるのでscoreのような名前の方が分かりやすいかもしれません。)
Kerasではこの計算をK.function()を使って行います。この時バックエンドではTensorFlowまたはTheanoが呼び出されます。CNNの場合、CPUによる計算はTensorFlowの方が速く、GPUによる計算は(今のところ)Theanoの方が速いようです(参考)。Kerasの良い所の一つはコードを全く変更することなくバックエンドを簡単に切り換えられることで、.keras/keras.jsonという設定ファイルを変更するだけで切り換えることができます。
layer_name = 'conv3' # 可視化したい層
filter_index = 0 # 可視化したいフィルタ
# 損失関数を作成
layer_output = layer_dict[layer_name].output
loss = K.mean(layer_output[:, filter_index, :, :])
# 勾配を計算。戻り値はリスト
grads = K.gradients(loss, input_img)[0]
# 勾配を規格化
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
# input_imgを与えるとlossとgradsを返す関数を作成
iterate = K.function([input_img, K.learning_phase()], [loss, grads])
小さすぎる、または大きすぎる勾配の影響を避けるために途中で勾配の規格化を行っていたりしますが、それ以外は入力データから損失関数と勾配を計算する準備をしているだけです。
注意しなければならないのは、K.learning_phase()も与えないとエラーが起きてしまうことです。これはテスト時か訓練時かを表すプレースホルダーです。最初に作成したモデルにはドロップアウトが含まれていますが、ドロップアウトは訓練時のみに適用され、テスト時には適用されません。そのため、テスト時か訓練時かを教えてあげる必要があります。
公式ブログで使用しているモデルは、全結合層を除いてドロップアウトが含まれていないためK.learning_phase()を与える必要はありません。
次に、計算した勾配を使ってイテレートすることにより、損失関数が大きくなる、すなわちフィルタによる活性化がより大きくなる入力データを探っていきます。
import numpy as np
# ランダムに初期化
input_img_data = np.random.random((1, 1, img_width, img_height)) * 20 + 128.
# gradient ascent
for i in range(20):
loss_value, grads_value = iterate([input_img_data, 0])
input_img_data += grads_value * step
[input_img_data, 0]の部分の0はテスト時であることを表し、K.learning_phase()に値を入れています。0はテスト時、1は訓練時であることを表します。
最後に、得られた入力データを加工して画像として出力します。
def deprocess_image(x):
# 平均0, 標準偏差が0.1になるように規格化
x -= x.mean()
x /= (x.std() + 1e-5)
x *= 0.1
# 値が[0, 1]の範囲になるようにクリップ
x += 0.5
x = np.clip(x, 0, 1)
# RGBの配列に変換
x *= 255
x = x.transpose((1, 2, 0))
x = np.clip(x, 0, 255).astype('uint8')
return x
img = input_img_data[0]
img = deprocess_image(img)
imsave('%s_filter_%d.png' % (layer_name, filter_index), img)
これでようやく可視化できるようになりました。

conv3を可視化
ちょっと見づらいですが、フィルタによる活性化が最大となる入力画像を出力することができました。学習に使用したFacial Keypoints Detectionの画像がグレースケールであるためグレースケールになっていますが、公式ブログのようにカラー画像で学習したモデルで試すとカラー画像が出てきてもっと楽しいかもしれません。また、この可視化の計算量は多くないのでGPUを使う必要はなく、CPUで十分計算できます。
畳み込み層だけでなく、全結合層も同様の手法で可視化することができます。
from keras.layers import Flatten, Dense
model.add(Flatten())
model.add(Dense(1000, name='dense1'))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1000, name='dense2'))
model.add(Activation('relu'))
model.add(Dense(30, name='dense3'))
上記のようにモデルの最後に全結合層を追加した後、
layer_output = model.layers[-1].output
loss = K.mean(layer_output[:, output_index])
とすることで可視化することができます。
ですが、今回扱っている問題は分類(classification)ではなく回帰(regression)なので意味のある画像が得られません。損失関数lossが最大になるような入力画像を表示していますが、損失関数が適切でないためです。例えば、左目の中心のx座標が最大になるような画像が得られても特に意味はないでしょう。回帰ではなく分類の場合は上記のやり方で可視化することができます。
Kerasによる可視化は以上です。重みの読み込みやK.learning_phase()などはまりやすいポイントが幾つかあるので、実装の参考になればと思います。
ImageNetを使って同様の方法で可視化を行っている論文があるので、その図を引用しておきたいと思います。

130万枚の画像・1000種類のクラスからなるILSVRC-2012のデータセットで学習。モデルの構成はAlexNet。Nguyen et al. 2015より引用
これらの画像はCNNが99.99%の信頼度であるクラスに属すると判定した画像です。クラス名はそれぞれ画像の下に表示されています。人間からするとどの画像もそれぞれのクラスと関係があるようには見えません。正則化(regularization)を行うと人間が認識できる画像に少し近づくことが知られていますが、その場合は信頼度が99.99%よりも僅かに落ちてしまいます。
同じ論文で、進化的アルゴリズム(evolutionary algorithm)によって画像を生成することも行っています。

どれもCNNは99.6%以上の信頼度で判定した画像なのですが、人間にはとてもそのようなクラスの画像には見えません。どうやらCNNは人間とは違った認識の仕方をしているようです。
可視化してCNNを調べる方法は他にもあって、逆畳み込み(deconvolution)を行って可視化している論文もあります。

この論文では可視化を行っているだけでなく、AlexNetから一部の畳み込み層や全結合層を取り除いてみたりした実験や、ImageNetを使って事前学習させた実験も行っています。全結合層のニューロン数は結果にほとんど影響を与えないなど、参考になる部分がたくさんあるかと思います。
全結合層のみ学習(前回モデル)
ここでは前回記事でも紹介したKaggleのFacial Keypoints Detectionを使って実装してみたいと思います。転移学習は前回記事でも紹介しましたが、今回は前回とは異なる方法を紹介したいと思います。前回は最後の全結合層を付け替えた後、ニューラルネットワーク全体で学習し直していましたが、今回は全結合層のみで学習を行います。畳み込み層部分を特徴抽出器として扱い、下図の部分の特徴を一度だけ抽出して保存します。
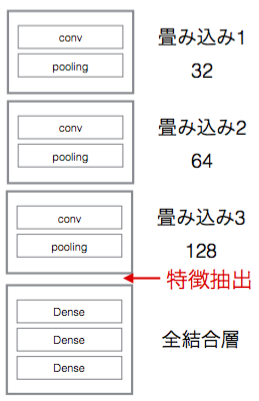
コードは以下です。GitHub上でも確認することができます。
# -*- encoding: utf-8 -*-
import os
import h5py
import numpy as np
from pandas.io.parsers import read_csv
from sklearn.cross_validation import train_test_split
from collections import OrderedDict
from keras.models import Sequential
from keras.layers import Convolution2D, Activation, MaxPooling2D
from keras import backend as K
from sklearn.utils import shuffle
from matplotlib import pyplot
# ダウンロード:https://www.kaggle.com/c/facial-keypoints-detection/data
FTRAIN = 'data/training.csv'
FTEST = 'data/test.csv'
# ダウンロード:https://github.com/elix-tech/kaggle-facial-keypoints
weights_path = '../examples/model6_weights_5000.h5'
img_width = 96
img_height = 96
def load(test=False, cols=None):
fname = FTEST if test else FTRAIN
df = read_csv(os.path.expanduser(fname))
df['Image'] = df['Image'].apply(lambda im: np.fromstring(im, sep=' '))
if cols:
df = df[list(cols) + ['Image']]
print(df.count())
df = df.dropna()
X = np.vstack(df['Image'].values) / 255.
X = X.astype(np.float32)
if not test:
y = df[df.columns[:-1]].values
y = (y - 48) / 48
X, y = shuffle(X, y, random_state=42)
y = y.astype(np.float32)
else:
y = None
return X, y
def load2d(test=False, cols=None):
X, y = load(test, cols)
X = X.reshape(-1, 1, 96, 96)
return X, y
def flip_image(X, y):
flip_indices = [
(0, 2), (1, 3),
(4, 8), (5, 9), (6, 10), (7, 11),
(12, 16), (13, 17), (14, 18), (15, 19),
(22, 24), (23, 25),
]
X_flipped = np.array(X[:, :, :, ::-1])
y_flipped = np.array(y)
y_flipped[:, ::2] = y_flipped[:, ::2] * -1
for i in range(len(y)):
for a, b in flip_indices:
y_flipped[i, a], y_flipped[i, b] = (y_flipped[i, b], y_flipped[i, a])
return X_flipped, y_flipped
def save_bottleneck_features():
model = Sequential()
model.add(Convolution2D(32, 3, 3, input_shape=(1, img_width, img_height)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.1))
model.add(Convolution2D(64, 2, 2))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Convolution2D(128, 2, 2))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.3))
assert os.path.exists(weights_path), 'Model weights not found (see "weights_path" variable in script).'
f = h5py.File(weights_path)
layer_names = [n.decode('utf8') for n in f.attrs['layer_names']]
weight_value_tuples = []
for k, name in enumerate(layer_names):
if k >= len(model.layers):
# 全結合層の重みは読み込まない
break
g = f[name]
weight_names = [n.decode('utf8') for n in g.attrs['weight_names']]
if len(weight_names):
weight_values = [g[weight_name] for weight_name in weight_names]
layer = model.layers[k]
symbolic_weights = layer.trainable_weights + layer.non_trainable_weights
if len(weight_values) != len(symbolic_weights):
raise Exception('Layer #' + str(k) +
' (named "' + layer.name +
'" in the current model) was found to '
'correspond to layer ' + name +
' in the save file. '
'However the new layer ' + layer.name +
' expects ' + str(len(symbolic_weights)) +
' weights, but the saved weights have ' +
str(len(weight_values)) +
' elements.')
weight_value_tuples += zip(symbolic_weights, weight_values)
K.batch_set_value(weight_value_tuples)
f.close()
print('Model loaded.')
X, y = load2d()
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# 水平反転させた画像を事前に作成しておく
X_flipped, y_flipped = flip_image(X_train, y_train)
X_train = np.vstack((X_train, X_flipped))
y_train = np.vstack((y_train, y_flipped))
bottleneck_features_train = model.predict(X_train)
np.save(open('bottleneck_features_train.npy', 'w'), bottleneck_features_train)
np.save(open('label_train.npy', 'w'), y_train)
bottleneck_features_validation = model.predict(X_val)
np.save(open('bottleneck_features_validation.npy', 'w'), bottleneck_features_validation)
np.save(open('label_validation.npy', 'w'), y_val)
save_bottleneck_features()
前回記事では、データをモデルに読み込ませる直前に50%の確率で画像を水平反転させていました。しかし、保存しておいた特徴を入力として学習させる場合はData augmentationを使えなくなってしまいます。そこで、事前に反転させた画像も作成しておき、その特徴も抽出しておきます。Razavian et al. 2014でも抽出した特徴を線形SVMの入力として使うという実験を行っているのですが、やはりData augmentationを行った方が良い結果が得られるということが報告されています。
ここでは特徴を一度だけ抽出して保存するだけなので、CPUでも十分計算することができます。
次に抽出した特徴を入力として全結合層を学習させます。前回記事のmodel8のように、特定のkeypointsに特化したモデルを複数作成します。
from keras.layers import Flatten, Dense, Dropout
from keras.optimizers import SGD
from keras.callbacks import LearningRateScheduler, EarlyStopping
SPECIALIST_SETTINGS = [
dict(
columns=(
'left_eye_center_x', 'left_eye_center_y',
'right_eye_center_x', 'right_eye_center_y',
),
flip_indices=((0, 2), (1, 3)),
),
dict(
columns=(
'nose_tip_x', 'nose_tip_y',
),
flip_indices=(),
),
dict(
columns=(
'mouth_left_corner_x', 'mouth_left_corner_y',
'mouth_right_corner_x', 'mouth_right_corner_y',
'mouth_center_top_lip_x', 'mouth_center_top_lip_y',
),
flip_indices=((0, 2), (1, 3)),
),
dict(
columns=(
'mouth_center_bottom_lip_x',
'mouth_center_bottom_lip_y',
),
flip_indices=(),
),
dict(
columns=(
'left_eye_inner_corner_x', 'left_eye_inner_corner_y',
'right_eye_inner_corner_x', 'right_eye_inner_corner_y',
'left_eye_outer_corner_x', 'left_eye_outer_corner_y',
'right_eye_outer_corner_x', 'right_eye_outer_corner_y',
),
flip_indices=((0, 2), (1, 3), (4, 6), (5, 7)),
),
dict(
columns=(
'left_eyebrow_inner_end_x', 'left_eyebrow_inner_end_y',
'right_eyebrow_inner_end_x', 'right_eyebrow_inner_end_y',
'left_eyebrow_outer_end_x', 'left_eyebrow_outer_end_y',
'right_eyebrow_outer_end_x', 'right_eyebrow_outer_end_y',
),
flip_indices=((0, 2), (1, 3), (4, 6), (5, 7)),
),
]
def fit_specialists():
specialists = OrderedDict()
start = 0.01
stop = 0.001
nb_epoch = 300
train_data = np.load(open('bottleneck_features_train.npy'))
train_labels = np.load(open('label_train.npy'))
validation_data = np.load(open('bottleneck_features_validation.npy'))
validation_labels = np.load(open('label_validation.npy'))
df = read_csv(os.path.expanduser(FTRAIN))
for setting in SPECIALIST_SETTINGS:
cols = setting['columns']
indices = [index for index, column in enumerate(df.columns) if column in cols]
train_labels_specialist = train_labels[:, indices]
validation_labels_specialist = validation_labels[:, indices]
model_specialist = Sequential()
model_specialist.add(Flatten(input_shape=train_data.shape[1:]))
model_specialist.add(Dense(1000))
model_specialist.add(Activation('relu'))
model_specialist.add(Dropout(0.5))
model_specialist.add(Dense(1000))
model_specialist.add(Activation('relu'))
model_specialist.add(Dense(len(cols)))
sgd = SGD(lr=start, momentum=0.9, nesterov=True)
model_specialist.compile(loss='mean_squared_error', optimizer=sgd)
early_stop = EarlyStopping(patience=100)
learning_rates = np.linspace(start, stop, nb_epoch)
change_lr = LearningRateScheduler(lambda epoch: float(learning_rates[epoch]))
print("Training model for columns {} for {} epochs".format(cols, nb_epoch))
hist = model_specialist.fit(train_data, train_labels_specialist,
nb_epoch=nb_epoch,
validation_data=(validation_data, validation_labels_specialist),
callbacks=[change_lr, early_stop])
model_specialist.save_weights("model_{}.h5".format(cols[0]))
np.savetxt("model_{}_loss.csv".format(cols[0]), hist.history['loss'])
np.savetxt("model_{}_val_loss.csv".format(cols[0]), hist.history['val_loss'])
specialists[cols] = model_specialist
fit_specialists()
学習曲線は以下のようになりました。
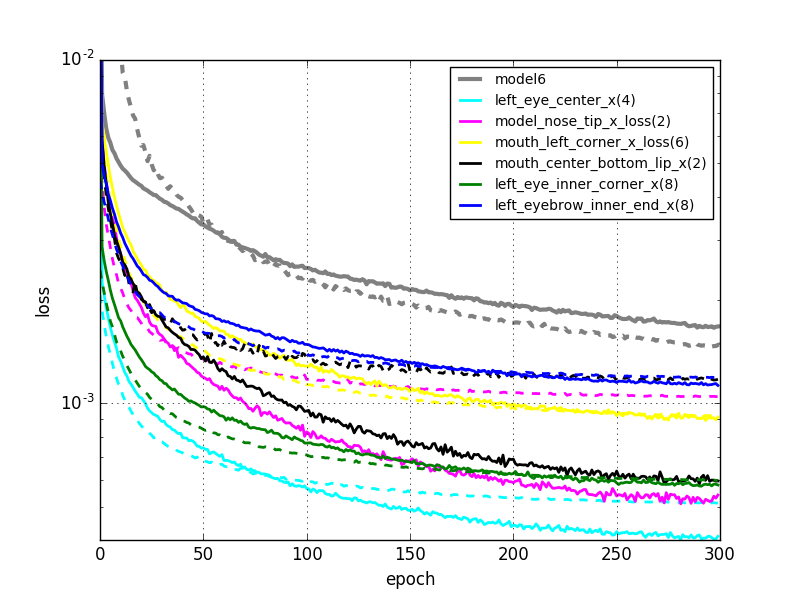
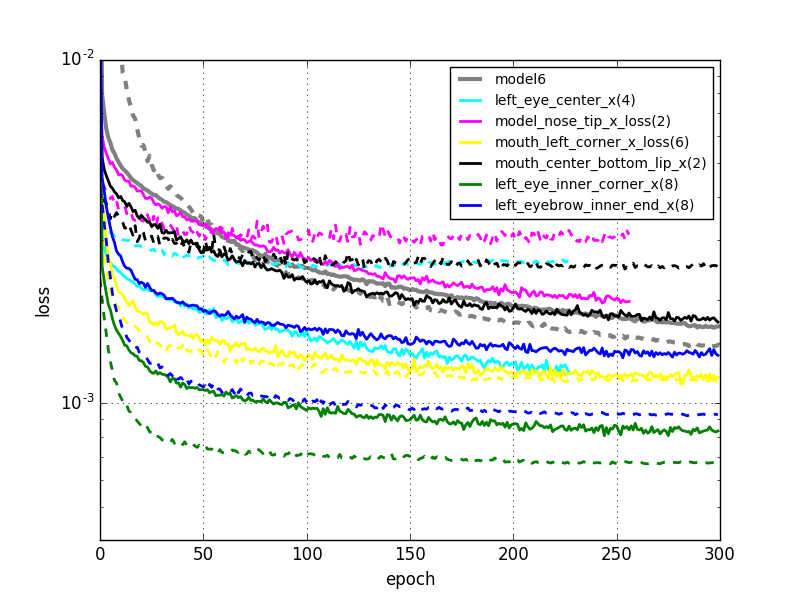
左図:今回。右図:前回。
前回の結果と比較して、明らかにエラーが小さくなりました。正直この結果は意外でした。計算速度は圧倒的に上がるメリットがあるとは思っていたのですが、エラーは同程度か僅かに大きくなってしまうだろうと思っていたからです。前回のモデルでは全結合層だけでなくネットワーク全体で学習していて、データも事前学習に使用したものと全く同じデータを使用しているので過学習も心配する必要はないはずです。
これは推測ですが、前回モデルでは全ての層で共通の値の学習係数を使用していたのが、良くなかったのではないかと思います。畳み込み層では学習が進んでいるため、より小さな学習係数の方が適切であると考えられます。そのため、今回のモデルでは畳み込み層では学習を行わなかったことが返って良い結果に繋がったのかもしれません。
計算時間は、GPUを使って6つの特化モデル合計で約1時間でした。前回のモデルでは6時間以上かかっていたことを考えると、圧倒的に速くなっていることが分かります。これくらい計算時間が短くなると、モデル毎にチューニングを行っていくことも容易になりそうです。
全結合層+一部の畳み込み層で学習(前回モデル)
Kerasでは一部の層をフリーズさせる(学習しない)ことができます。ここで実装方法を紹介しておきたいと思います。下図のように下層だけをフリーズさせ、上層でのみ学習を行うようにしてみます。
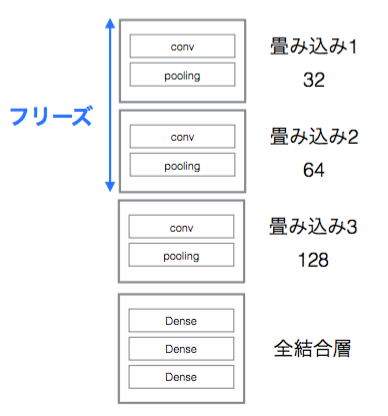
コードは以下のようになります。GitHub上でも確認することができます。
weights_path = '../examples/model6_weights_5000.h5'
model = Sequential()
model.add(Convolution2D(32, 3, 3, input_shape=(1, img_width, img_height)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.1))
model.add(Convolution2D(64, 2, 2))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Convolution2D(128, 2, 2))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.3))
model.add(Flatten())
model.add(Dense(1000))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1000))
model.add(Activation('relu'))
model.add(Dense(30))
model.load_weights(weights_path)
for layer in model.layers[:8]:
layer.trainable = False
layer.trainable = Falseのようにすることで非常に簡単にフリーズさせることができます。ここでは8層目までフリーズさせています。KerasではDropout、Activation、Flattenも層として数えられ、このモデルの場合は全部で19層になります。
model6_weights_5000.h5は同じモデル・データで学習したのものであるため、この例は転移学習というよりも実際には単に学習の続きをやっているだけですが、Kerasで一部の層をフリーズさせる時の参考になればと思い紹介してみました。
全結合層のみ学習(VGG)
これまでの章ではFacial Keypoints Detectionのデータを使って学習させたモデルを使用していましたが、ここでは異なるモデル・データを使って転移学習させてみたいと思います。2014年のILSVR (Image Net)コンペで優勝したモデルをベースとするVGG16というモデルを使います。学習済みの重みのデータも公開されています。

上図のように全結合層の手前の所で特徴を抽出し、ファイルに保存します。
コードは以下のようになります。GitHub上でも確認することができます。
import os
import h5py
import numpy as np
from pandas.io.parsers import read_csv
from sklearn.cross_validation import train_test_split
from keras.models import Sequential
from keras.layers import ZeroPadding2D, Convolution2D, MaxPooling2D
from sklearn.utils import shuffle
# ダウンロード: https://www.kaggle.com/c/facial-keypoints-detection/data
FTRAIN = 'data/training.csv'
FTEST = 'data/test.csv'
# ダウンロード: https://gist.github.com/baraldilorenzo/07d7802847aaad0a35d3
weight_path = '../examples/vgg16_weights.h5'
img_width = 96
img_height = 96
def gray_to_rgb(X):
X_transpose = np.array(X.transpose(0, 2, 3, 1))
ret = np.empty((X.shape[0], img_width, img_height, 3), dtype=np.float32)
ret[:, :, :, 0] = X_transpose[:, :, :, 0]
ret[:, :, :, 1] = X_transpose[:, :, :, 0]
ret[:, :, :, 2] = X_transpose[:, :, :, 0]
return ret.transpose(0, 3, 1, 2)
def save_bottleneck_features():
model = Sequential()
model.add(ZeroPadding2D((1, 1), input_shape=(3, img_width, img_height)))
model.add(Convolution2D(64, 3, 3, activation='relu', name='conv1_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(64, 3, 3, activation='relu', name='conv1_2'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(128, 3, 3, activation='relu', name='conv2_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(128, 3, 3, activation='relu', name='conv2_2'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_2'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_3'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_2'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_3'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_2'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_3'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
assert os.path.exists(weight_path), 'Model weights not found (see "weights_path" variable in script).'
f = h5py.File(weight_path)
for k in range(f.attrs['nb_layers']):
if k >= len(model.layers):
break
g = f['layer_{}'.format(k)]
weights = [g['param_{}'.format(p)] for p in range(g.attrs['nb_params'])]
model.layers[k].set_weights(weights)
f.close()
print('Model loaded.')
X, y = load2d()
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# 水平反転
X_flipped, y_flipped = flip_image(X_train, y_train)
X_train = np.vstack((X_train, X_flipped))
y_train = np.vstack((y_train, y_flipped))
# グレースケールからRGBに変換
X_train = gray_to_rgb(X_train)
X_val = gray_to_rgb(X_val)
bottleneck_features_train = model.predict(X_train)
np.save(open('bottleneck_features_train.npy', 'w'), bottleneck_features_train)
np.save(open('label_train.npy', 'w'), y_train)
bottleneck_features_validation = model.predict(X_val)
np.save(open('bottleneck_features_validation.npy', 'w'), bottleneck_features_validation)
np.save(open('label_validation.npy', 'w'), y_val)
save_bottleneck_features()
Facial Keypoints Detectionの画像はグレースケールですが、VGGはRGBの画像を使って学習しているため、画像をRGBに変換する作業も行っています。
VGGはより大きなネットワークなのでより時間がかかりますが、特徴は一度抽出するだけなので、CPUだけでも十分実行することができます。次に、抽出した特徴を使って全結合層で学習を行います。
from keras.layers import Flatten, Dense, Dropout
from keras.optimizers import SGD
from keras.callbacks import LearningRateScheduler
def train_top_model():
start = 0.03
stop = 0.001
nb_epoch = 300
train_data = np.load(open('bottleneck_features_train.npy'))
train_labels = np.load(open('label_train.npy'))
validation_data = np.load(open('bottleneck_features_validation.npy'))
validation_labels = np.load(open('label_validation.npy'))
model = Sequential()
model.add(Flatten(input_shape=train_data.shape[1:]))
model.add(Dense(1000, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000, activation='relu'))
model.add(Dense(30))
sgd = SGD(lr=start, momentum=0.9, nesterov=True)
model.compile(loss='mean_squared_error', optimizer=sgd)
learning_rates = np.linspace(start, stop, nb_epoch)
change_lr = LearningRateScheduler(lambda epoch: float(learning_rates[epoch]))
hist = model.fit(train_data, train_labels,
nb_epoch=nb_epoch,
validation_data=(validation_data, validation_labels),
callbacks=[change_lr])
np.savetxt('model_top_loss.csv', hist.history['loss'])
np.savetxt('model_top_val_loss.csv', hist.history['val_loss'])
train_top_model()
これは中間層が2層のニューラルネットワークなので、CPUでも計算可能です。得られた学習曲線は以下です。
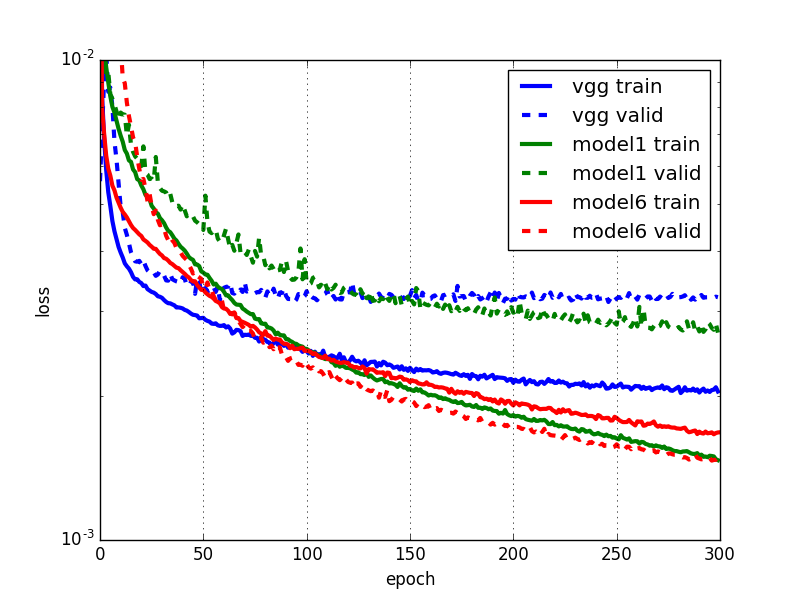
vgg: 今回のモデル。model1: 前回記事の中間層1層のMLP。model6: 前回記事のCNN
残念ながら事前学習したVGGを使って特徴抽出を行っても、Facial Keypoints Detectionに関しては特に良い結果は得られないようです。2つ目の中間層の後にもドロップアウトを入れてみたり、model1と同じ構成の普通のニューラルネットワークにしてみたりもしたのですが、ほとんど結果は変わりませんでした。
ImageNetとFacial Keypoints Detectionの主な違いとしては、
- 1000種類のクラスか、人の顔だけか
- カラーかグレースケールか
- 分類か回帰か
が挙げられます。
Razavian et al. 2014では、ImageNetで学習したAlexNetを使って様々なデータセットから特徴を抽出し、線形SVMを使ってどれくらいパフォーマンスが出るかを調査しています。特徴抽出に使用するモデルはImageNetに最適化されているにも関わらず、11,788枚・200種類の鳥の画像からなるCaltech-UCSD Birds (CUB) 200-2011や、102種類の花で構成されるOxford 102 flowersという似たような画像を集めたデータセットの場合でも良い結果が出るということが報告されています。
このような背景があったため、もしかしたら良い結果が得られるかもしれないという期待もあったのですが、どうやらこの場合はうまくいかないようです。転移学習の章で紹介したパターンでいうと「データが少ない・似ていない」という転移学習が困難なパターンに相当しているのかもしれません。
まとめ
転移学習の手法やその使い分けを始めに紹介し、途中で可視化の話も交えつつ、後半の章では実際に実装してみました。前回記事で紹介した方法に比べて圧倒的に計算速度が上がり、さらにエラーが小さくなりました。
最後に紹介したVGGのように大きなニューラルネットワーク、大きなデータセットを使って学習した重みが公開されていたりします。ディープラーニングを使う際に、学習に使えるデータの量が限られていたり、学習に時間が掛かり過ぎるなどの問題に直面することもあるかと思いますが、転移学習を使ってうまく解決できる場面が多くあるのではないかと思います。
参考文献
- The Keras Blog
- Keras Documentation
- CS231n Convolutional Neural Networks for Visual Recognition
- Simonyan et al. 2015, VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
- Razavian et al. 2014, CNN Features off-the-shelf: an Astounding Baseline for Recognition
- Erhan et al. 2009, Visualizing Higher-Layer Features of a Deep Network
- Simonyan et al. 2014, Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
- Krizhevsky et al. 2012, ImageNet Classification with Deep Convolutional Neural Networks
- Zeiler and Fergus 2014, Visualizing and Understanding Convolutional Networks
- Nguyen et al. 2015, Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images